HTML Entities & Charset & URL Encode
HTML Entities
Character entities are used to display reserved characters in HTML. 字符实体用于显示HTML的保留字符。许多通用键盘上没有的数学符号、科技符号、货币符号等,也可以通过HTML实体来表示。
有两种写法:
&entity_name;
OR
&#entity_number;
优点:使用前者(实体名字)便于记忆。
缺点:The browsers may not support all entity names, but the support for numbers(十进制或十六进制)is good. 浏览器不一定支持(能识别)所有的实体名称。
Tips:
- If you use an HTML entity name, or number, the character will always display correctly. This is independent of what character set (encoding) your page uses! 无论用实体名还是数字,字符都会正确显示,这个是独立于网页所使用的编码字符集的。
- Remember that browsers will always truncate spaces in HTML pages. If you write 10 spaces in your text, the browser will remove 9 of them. 为了在文本中加入1个以上的空格,可以使用
字符实体。 - Symbols 实体用法一样。
注意: Entity names 是 case sensitive 大小写敏感的!
HTML Charset
为正确显示网页,浏览器必须知道使用哪种 character set (character encoding)字符集/编码。
ASCII was the first character encoding standard (also called character set). ASCII supported numbers (0-9), English letters (A-Z), and some special characters like ! $ + - ( ) @ < > .
ASCII,代表美国信息交换标准码。它是一个7位字符代码,每个位代表一个唯一的字符。
一些符号正则表达式检测不出来
网络上找到的ascii字符表,测试发现编码在 \x80-\x9f 范围内的符号用 /^[\x00-\xff]+$/ 这个正则表达式检测不出来。
以8位,256个字符,根据 Windows-1252(代码页1252)编码的 ASCII 表,它是 ISO 8859-1 在可打印字符方面的超集。其中在128到159(十六进制80到9F)范围内,ISO / IEC 8859-1具有不可见的控制字符,而 Windows-1252 替换为额外的一些常用,但未包含在 ISO-8859-1 中的字符。
扩展表里显示的128-159的字符是Windows-1252 (CP-1252)可打印字符,实际对应的 ascii 编码不在\x00-\xff范围内,所以正则校验不通过。
Unicode
Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准,它对世界上大部分的文字系统进行了整理、编码,并广泛地应用于电脑软件的国际化与本地化过程,如可扩展置标语言(Extensible Markup Language,简称:XML)、Java编程语言以及现代的操作系统。
一个字符的 Unicode 编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对 Unicode 编码的实现方式有所不同。
Unicode 的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF),目前通用的实现方式是UTF-16小端序(LE)、UTF-16大端序(BE)和UTF-8。
The default character encoding was changed to UTF-8 in HTML5(All HTML 4 processors also support UTF-8).
HTML5
<meta charset="UTF-8">
HTML4
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-1">
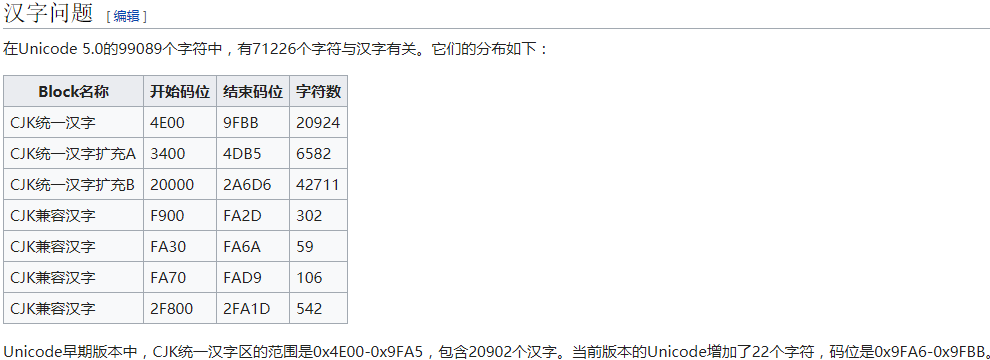
中文Unicode字符集
HTML URL(Uniform Resource Locators)
URL 也就是 web address。通常人们容易记住映射成单词的网址,而不会去刻意记住ip地址形式的url。
URL 格式
scheme://host.domain:port/path/filename
说明:
- scheme - defines the type of Internet service.(most common type is https)
- host - defines the domain host (default host for http is www)
- domain - defines the Internet domain name, like w3schools.com
- port - defines the port number at the host (default port number for http is 80)
- path - defines a path at the server (If omitted, the document must be stored at the root directory of the site)
- filename - defines the name of a document/resource
URL Encoding
URLs can only be sent over the Internet using the ASCII character-set.
Since URLs often contain characters outside the ASCII set (因为URL 中经常含有ASCII字符集以外的字符,比如请求参数里含有字母、带有音标,如法语西语字母), we must converts characters into a format that can be transmitted over the Internet. 此时必须使用URL编码把这些字符转换为可以在因特网中传输的形式。
URL encoding replaces non ASCII characters with a “%” followed by 2 hexadecimal digits. URL编码用一个 % 紧跟着两个十六进制数字来替换URL中非ASCII字符。(比如 € 欧元符号,编码为:%E2%82%AC)
URLs cannot contain spaces, normally replaces a space with a plus (+) sign or %20. URL中不能含有空格,通常用一个加号替换空格。
URL编码/转义尽量使用 encodeURI()、 encodeURIComponent()。解码使用想对应的 decodeURI()、decodeURIComponent()。
区别:encodeURI 应当用于整个 URI 的编码,encodeURIComponent 则用于 URI 中某个部分的编码。
encodeURI('https://www.baidu.com/ a b c') // "https://www.baidu.com/%20a%20b%20c"
encodeURIComponent('https://www.baidu.com/ a b c') // "https%3A%2F%2Fwww.baidu.com%2F%20a%20b%20c"
encodeURIComponent(' a b c') // "%20a%20b%20c"
注意:不要使用几乎废弃的 escape(),unescape(),否则会引入 % 开头的非法字符串。其他人使用上面的函数进行解析时会报错。
如: unescape('%u0107'),使用上面的函数解析会报错